


通过使用为自然语言处理开发的技术,研究人员可以预测病毒如何进化(图片来源:Mingxi Cheng)
现在是2020年;一种被深深误解的病原体正在世界各地传播,无论它走到哪里,都会感染人们。当它从地球的一个角落反弹到另一个角落时,它会发生变异,让专家们争先解决这个问题。
但病原体不是COVID-19。这是错误的信息——就像几个月前帮助破坏我们国家对民主信仰的QAnon阴谋论一样。
在某些方面,基因突变和谣言并没有太大的不同。事实上,这种认识是一些令人兴奋的新研究发表的前提自然科学报告.这项工作实际上可能有助于在下一次大流行或生物攻击开始之前就阻止它们。
南加州大学维特比工程学院的三位研究人员bob国际首页登录Mingxi程,博士生,萨因Nazarian,电气与计算机工程副教授,以及保罗·波格丹杰克·穆努希安(Jack Munushian)早期职业生涯主席、电气与计算机工程副教授有一个关键的见解:一种识别在线谣言如何变异为全面假新闻的算法可以被重新训练和重新分类,以检测像COVID-19这样的病毒的下一个变异。
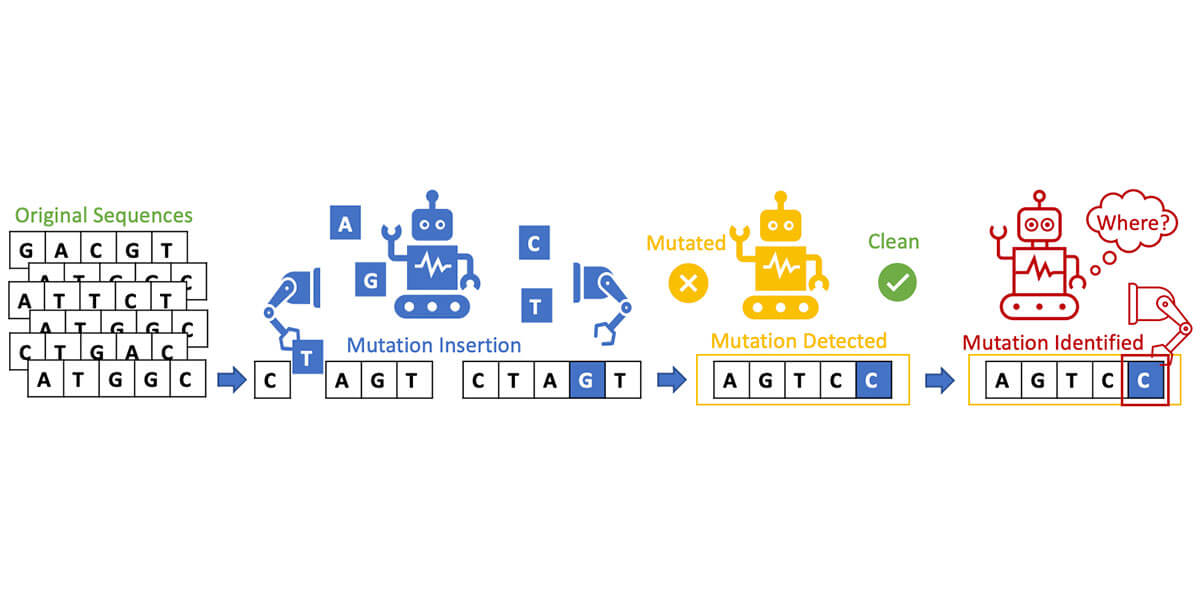
DNA就像语言一样,是由a、C、G和t这一系列字母组成的。一段时间以来,Bogdan的研究小组一直在开发一种算法,用于在线识别虚假或篡改的语言,这在当今虚假信息的世界中是一项重要的工作。这些类型的自然语言处理算法会查看被坏人修改过的句子和流行语。他们也可以观察DNA序列,并对密码中的数十亿个字母做同样的事情吗?
程说:“首先,我们建立了一个生成算法,可以稍微改变句子中的语言。”“然后,我们建立了一个鉴别算法来查看更改的语言,并捕捉任何虚假或更改的语句。”但远不止于此。
“这项跨学科研究显示了自然语言处理模型的新潜力……也许人类的语言与基因的语言并没有太大的不同。”——Mingxi Cheng
要让判别算法真正发挥作用,它不能仅仅识别错误信息。它必须能够学习如何首先就会产生错误信息。Cheng将其与Frank Abagnale进行了比较,Frank Abagnale是一个现实生活中的伪造者,后来成为世界级的联邦调查局特工,因莱昂纳多·迪卡普里奥在电影《猫捉猫》中对他的演绎而闻名。阿巴格纳尔是他所做的最好的,因为他来自那个世界。他了解造假者的思维方式,也知道他们使用的策略。“最好的鉴别算法不仅仅是知道谣言的样子,”程说。“他们实际上可以学习如何谣言首先就产生了。”
在考虑了所有这些因素后,研究小组采用了他们的新模型,并让它观察序列中有一些改变字母的DNA。该模型快速准确地识别出DNA发生变化的位置和方式。无论研究人员的DNA在哪里、如何或有多轻微的改变,他们的模型都能识别出来。
现在,你可能会认为这没什么大不了的。我们已经我们知道地球上几乎所有东西的遗传密码,那么为什么我们需要一个算法来告诉我们什么时候发生了变化呢?难道我们不能简单地将可疑序列与原始序列进行比较吗?
这个问题的第一个答案很简单:速度。理论上,Bogdan和Cheng的模型可以很容易地构建到现有的DNA测序仪中,并赋予它们识别罪魁祸首DNA的能力。这意味着任何拥有测序仪的人都可以快速而廉价地捕捉“坏”DNA。
但这个问题的第二个答案非常重要。事实上,这些研究人员所做的只是对我们的物种和我们的星球产生更深远影响的第一步,尤其是在我们的后covid世界。Jack Munushian早期职业生涯主席Bogdan说:“我们的下一步是试图增强我们的模型,使我们能够观察病毒的基因组成,并预测未来危险的突变将在哪里以及如何发生。”有了这些知识,有一天可以开发出针对病毒的疫苗还没进化呢.
该团队在这一领域的工作确实是未知的领域。迄今为止,还没有人开发出具有这种精度水平的模型,如果成功的话,它将代表一种全新的医学工具。
事实上,如果我们拥有这样的技术,它可能意味着我们所知道的流行病的终结。“这项真正跨学科的研究显示了自然语言处理模型的新潜力,并为涉及基因序列突变的问题提供了一个新的角度。也许人类的语言和基因的语言并没有太大的不同。”
2021年4月6日出版
最后更新于2021年4月6日







